整合營銷服務商
電腦端+手機端+微信端=數據同步管理
免費咨詢熱線:

電腦端+手機端+微信端=數據同步管理
免費咨詢熱線:
因為最近搞畢業論文,有點忙,加上還有好多粉絲咨詢,臨近畢業更新就很少了。
今天就寫一個非常簡單的文章,敷衍一下吧,哈哈哈。
今天要寫的就是數據清洗的函數mutate(),這個屬于超級基本的內容哦,一般我們拿到數據最頭疼應該就是清洗數據了,所以清洗數據的基礎一定要牢牢掌握。
還有,如果你想成為一名合格的分析師,其實你只要精通清洗數據就夠了,我這么說一點都不夸張。
一個簡單數據清洗任務常常包括:
本文就只寫最后一個,即在R中使用mutate創建新變量。
mutate的基礎知識
在開始之前,我們先談談dplyr。
dplyr是R中專門用于數據處理的包。更具體功能包括:
在大多數情況下,dplyr僅執行這些任務。dplyr出色的部分原因在于它“緊湊”。只有5或6種主要工具,并且非常易于使用。
mutate()如何用?
使用時,通常你只需要指定3項內容:
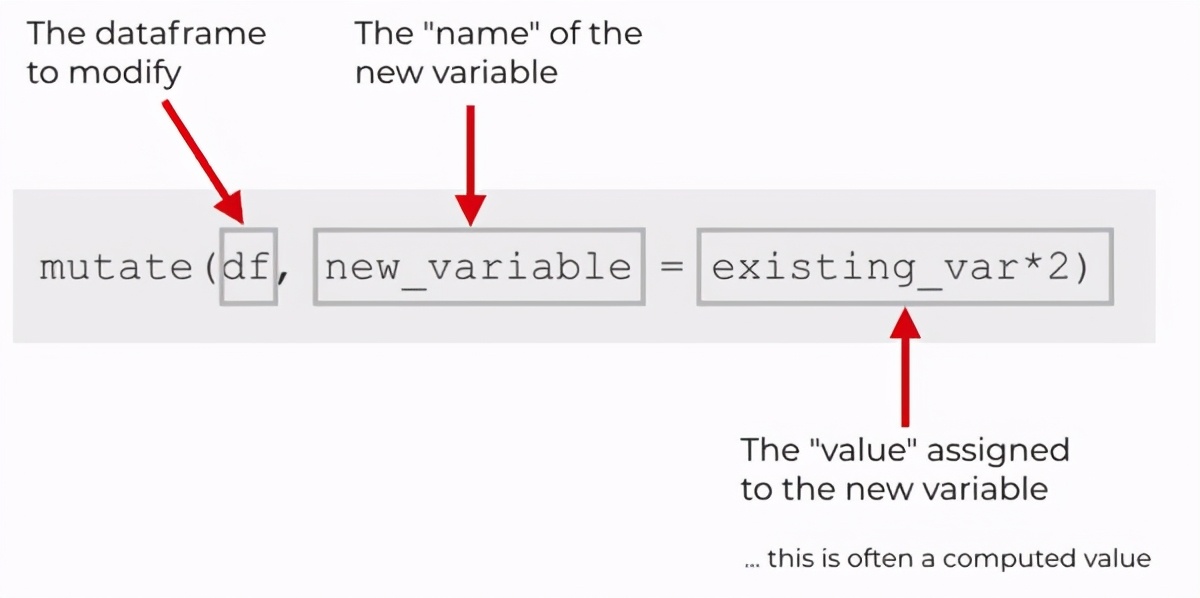
還是給大家舉個例子:看下圖,mutate()的第一個參數就是數據框,然后就是新變量名=舊變量的某種新式。就是說你可以輕松地以數據框中的原有變量生成新變量。
但是這個函數只能用于數據框,不能在列表,矩陣,向量或其他數據結構中使用。

注意,mutate()的第二個參數是“名稱-值”對,就是說我們在創建變量時新變量需要一個名稱,但是它也需要一個分配給該名稱的值。因此,當使用mutate時,您需要提供名稱和新值…即名稱/值對。
我們再次看一下剛剛的語法示例:
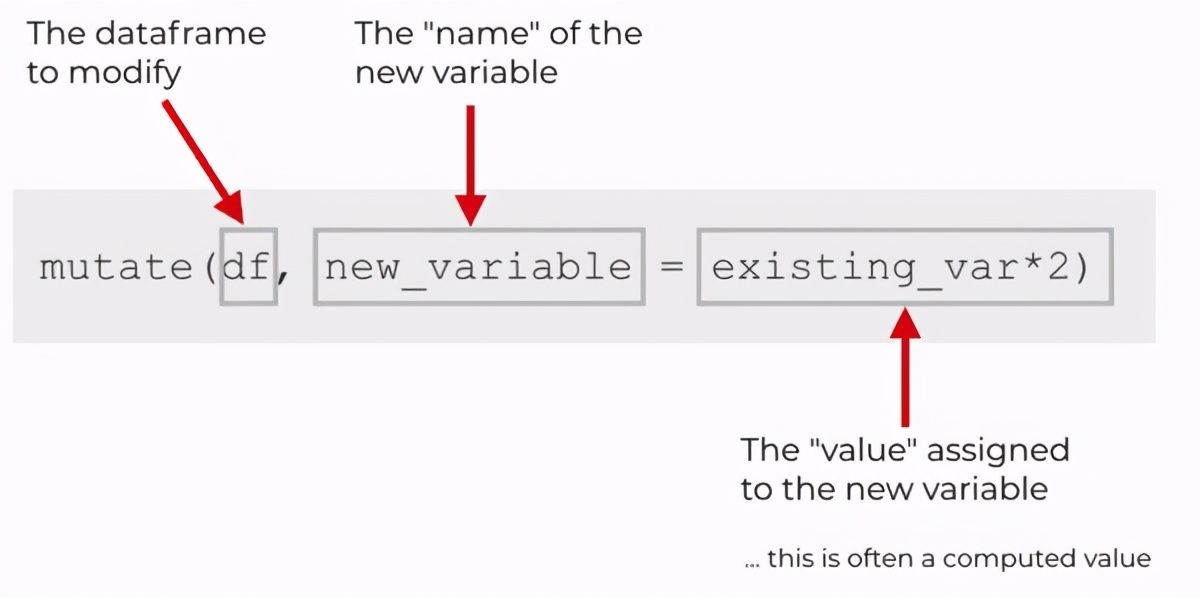
那么在上圖中我們是要創建一個名為的新變量。分配給的值為乘以2的值。在此示例中,變量為原本就存在于數據框df當中的。
就是這么簡單。
實例操作
為了加深大家的印象,還是給大家一個實例
library(dplyr)
library(ISLR)我們使用ISLR包中的Auto數據框給大家演示。
在我們對數據進行實際操作之前,讓我們先瞅一瞅它長啥樣。
print(Auto)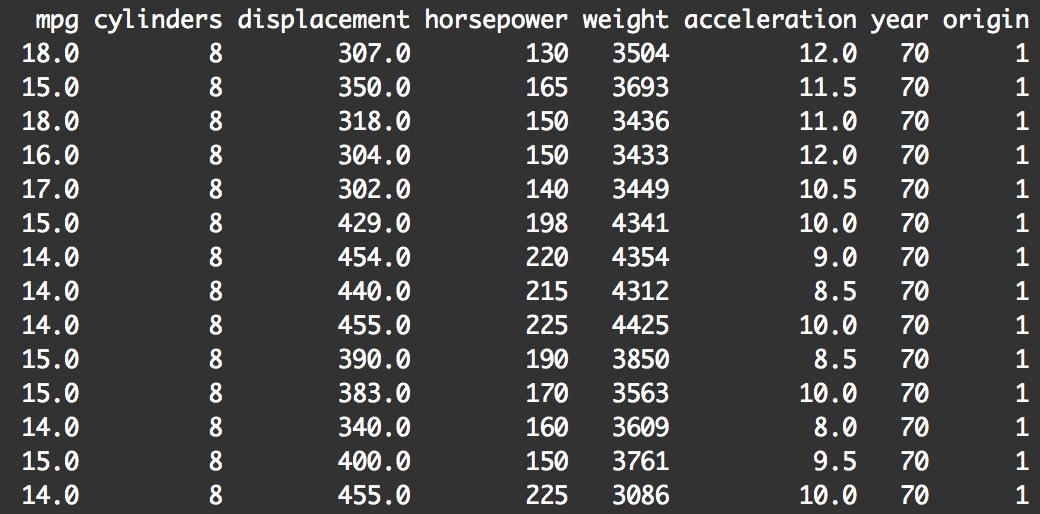
打印出來時,您會發現數據數據框排列的有些雜亂,我們可以將它轉化為tibble打印效果更好。tibble實際上是修改后的數據框。它的優點之一是它們以更好的格式打印出來。
auto_specs <- as.tibble(Auto)
print(auto_specs)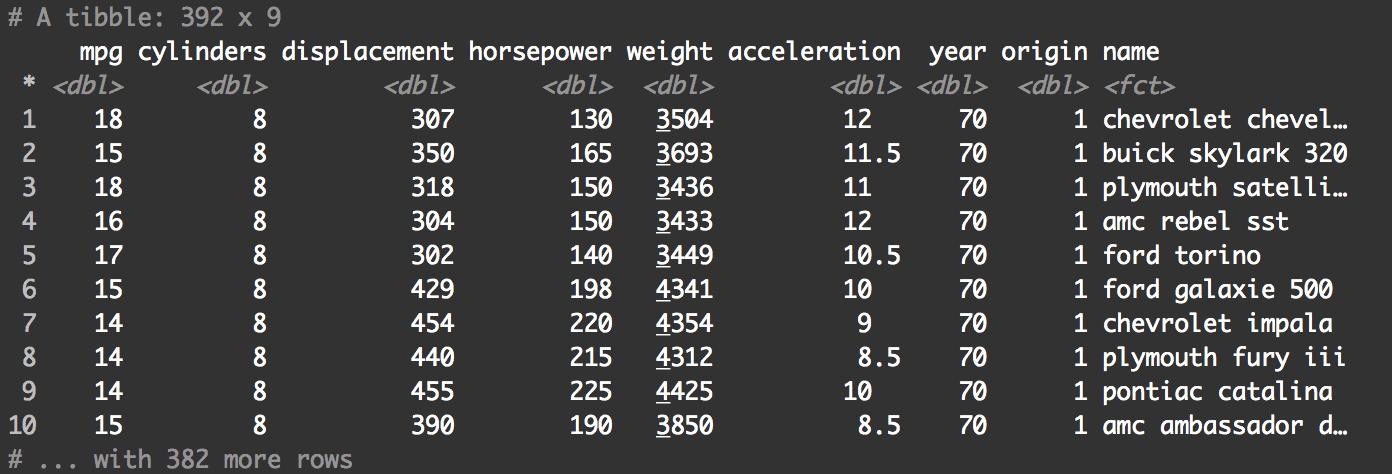
這樣好多了。
您可以看到,當我們現在打印出來時,tibble結構更具可讀性。
好了。比如我現在需要一個新變量叫做,這個變量是原先 / weight兩個變量的比值,我們就可以用使用mutate()寫出如下代碼:
auto_specs_new <- mutate(auto_specs, hp_to_weight = horsepower / weight)
print(auto_specs_new)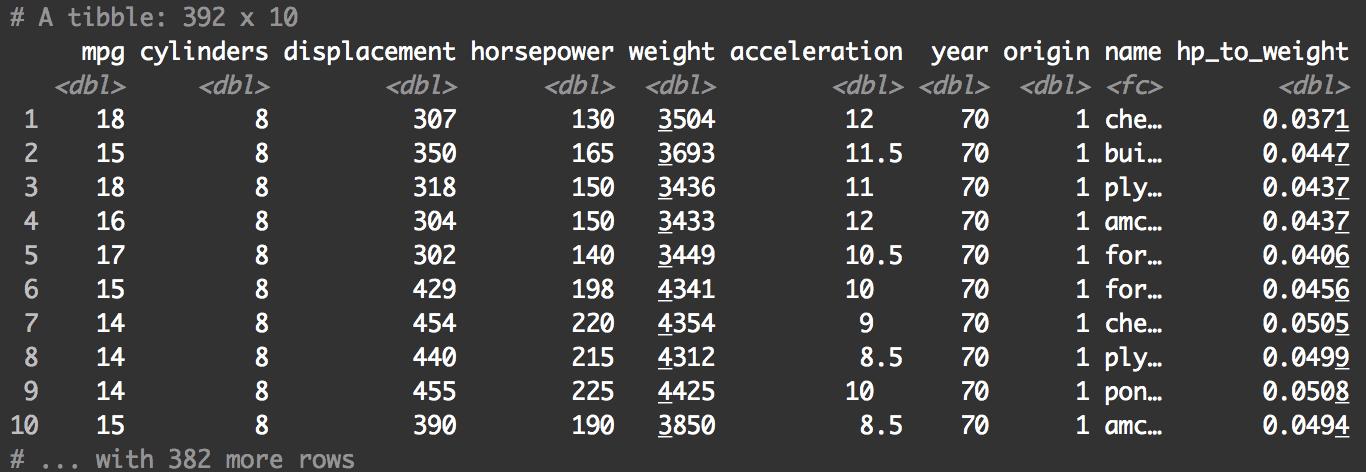
可以看到新的變量已經在這個數據框中了。在R中使用mutate()就是這么簡單。
小結
今天給大家寫了mutate()如何創建新變量,超級簡單的一個教程,感謝大家耐心看完,自己的文章都寫的很細,代碼都在原文中,希望大家都可以自己做一做,請關注后私信回復“數據鏈接”獲取所有數據和本人收集的學習資料。如果對您有用請先收藏,再點贊轉發。
也歡迎大家的意見和建議。
如果你是一個大學本科生或研究生,如果你正在因為你的統計作業、數據分析、論文、報告、考試等發愁,如果你在使用SPSS,R,Python,Mplus, Excel中遇到任何問題,都可以聯系我。因為我可以給您提供好的,詳細和耐心的數據分析服務。
如果你對Z檢驗,t檢驗,方差分析,多元方差分析,回歸,卡方檢驗,相關,多水平模型,結構方程模型,中介調節,量表信效度等等統計技巧有任何問題,請私信我,獲取詳細和耐心的指導。
If you are a student and you are worried about you #, #Data #, #Thesis, #reports, #, #Quizzes, Exams.. And if you are facing problem in #SPSS, #R-, #Excel, Mplus, then contact me. Because I could provide you the best for your Data .
Are you with like z-test, t-test, ANOVA, MANOVA, , , Chi-Square, , , SEM, model, and etc. for your Data ...??
Then Contact Me. I will solve your Problem...
加油吧,打工人!
使用PowerDesigner設計數據庫
原文鏈接:
設計數據庫有如下6個主要步驟:
1、需求分析:了解用戶的數據需求、處理需求、安全性及完整性要求;
2、概念設計:通過數據抽象,設計系統概念模型,一般為E-R模型;
3、邏輯結構設計:設計系統的模式和外模式,對于關系模型主要是基本表和視圖;
4、物理結構設計:設計數據的存儲結構和存取方法,如索引的設計;
5、系統實施:組織數據入庫、編制應用程序、試運行;
6、運行維護:系統投入運行,長期的維護工作。
在此我要說的是使用設計數據庫的設計過程,有些地方可能不太正確,望各位高手指正。
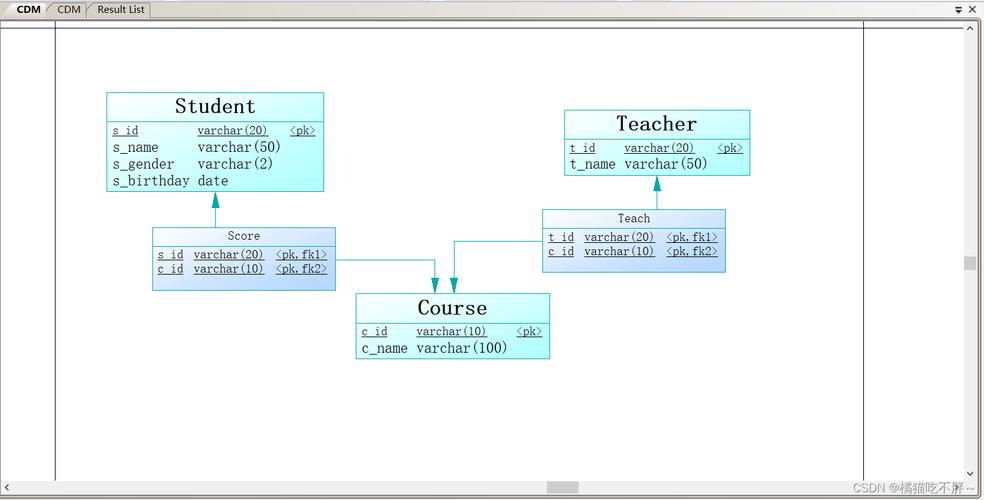
一、首先是需求分析,這個不用多說了,不同的數據庫有不同的需求,以下是分析這個數據庫需求之后設計出來的實體、實體間的關系和表格,其中的字段,屬性就不一一列出了:
二、通過這個表格使用設計數據庫:
1、概念模型設計
(1)創建模型:
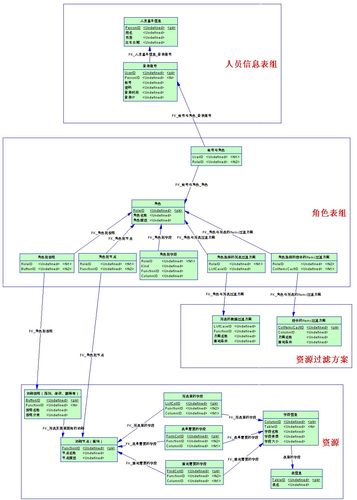
(2)創建表,添加屬性字段,根據實體間的對應關系,建立表與表之間的關系。
對于多對多關系的中間表(如角色菜單表),是不能創建的,只需設定它們的對應關系為多對多,在生成邏輯模型時會自動生成這張表,這張表的默認名為多對多的關系名,把這張的表名修改為自己想要的就行了。而“角色菜單操作”表涉及三張表的關聯也是不能創建的,這個在物理模型設計時再來解決。
對于表的外鍵,也是不能添加的,在指定實體關系之后,生成邏輯模型時也會自動添加到表中。
這個時候,有一些表示和其他表之間沒什么關聯的,它們依賴與多對多生成的表(如操作表),或者和其他表都沒什么關系(如數據字典表,這個只需創建好表即可,無須擔心),在生成物理模型時對依賴中間表的表可以進行關聯。
2、邏輯模型設計
生成邏輯模型
自動生成的角色菜單表:
3、物理模型設計
(1)生成物理模型,指定數據庫類型
(2)修改數據類型
生成的數據表中,有些數據類型可能不是你想要的,這個時候就可以打開數據表修改為自己想要的數據類型了:
(3)添加一張新的空表,分別指向角色、菜單、操作這三張表,生成角色菜單關系表:
(4)完成之后Ctrl+C保存所有的到一個新的文件夾中:
4、生成數據庫SQL語句
至此數據庫的SQL的語句生成了,只需在數據庫中創建一個數據庫,用來執行這些SQL語句即可。
三、生成數據庫設計文檔
完成數據庫設計之后,關閉,使用數據字典閱讀器生成設計文檔
還需要在設計文檔中填寫一些數據字典數據等內容。
到此,所有的設計工作都OK了!
*請認真填寫需求信息,我們會在24小時內與您取得聯系。
